


Dataset
In the paper, two main datasets are considered: NYUDv2 and KITTI, representing indoor and outdoor settings, respectively.
To account for the uneven distribution of the classes and tasks in the datasets, the paper adopts what's called Knowledge distillation, which refers to a training procedure for a neural network that transfers the knowledge from a teacher network to a student network. Particularly:
Due to similarities with the CityScapes dataset, we consider ResNet-38 trained on
CityScapes as our teacher network to annotate the training images that have depth
but
not semantic segmentation. In turn, to annotate missing depth annotations on 100
images
with semantic labels from KITTI-6, we first trained a separate copy of our network
on
the depth task only, and then used it as a teacher.
So, the Hydranet was firstly trained on the KITTI dataset for depth estimation, then knowledge from the Resnet38 was transferred to the Hydranet for semantic segmentation as well.
Model
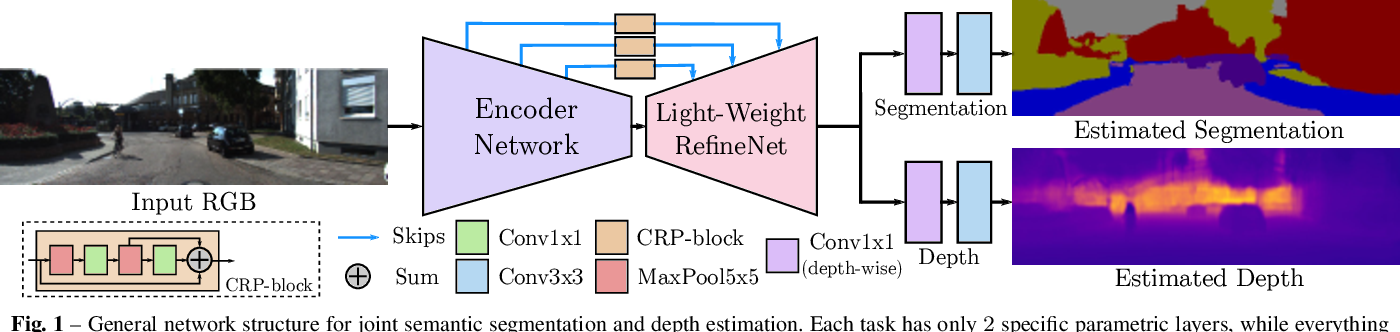
The proposed architecture relies on a Light-Weight RefineNet architecture built on top of the MobileNet-v2 classification network.
This architecture extends the classifier by appending several simple contextual blocks, called Chained Residual Pooling (CRP), consisting of a series of 5 x 5 max-pooling and 1 x 1 convolutions.
The branching happens right after the last CRP block, and two additional convolutional layers (one depthwise 1 x 1 and one plain 3 x 3) are appended for each task
Results
The following table shows the results from the paper:

Joint depth estimation and segmentation
Project repository
A Pytorch implementation of the paper Real Time Joint Semantic Segmentation & Depth Estimation Using Asymmetric Annotations
According to the classical multi-task learning paradigm, forcing a single model to perform several related tasks simultaneously can improve generalisation via imposing an inductive bias on the learned representations.
In this project, the related tasks are semantic segmentation and depth estimation. The aim is to demonstrate that there is no need to uncritically deploy multiple expensive models, when the same performance can be achieved with one small network.